模糊锚定(Fuzzy Anchoring)(一)
Nov 30, 2023Front End
概述
如果你使用过 goodnotes、notability 等软件,你可能会发现,当你为文档中的某些内容添加了一些 注释/标记 后,下次打开文档时,这些注释/标记 仍然可以准确地锚定在文档中的相应位置。但是如果对文档进行修改,就有可能导致这些 注释/标记 的位置产生偏移,甚至丢失。这些 注释/标记 的准确性高度依赖于锚定位置的可信度,对于变更频繁的文档,锚定的可信度就会降低。
网页呈现在浏览器中,也是一种文档,以人的肉眼和认知系统来看,一段文字即使发生一些改变,依靠记忆和内容上下文,我们也能很快地找到他。但网页是由浏览器将其转换为 DOM树 来渲染的,即便是一些微小的改变(甚至渲染出来的内容完全不变),也可能导致 DOM 结构的变化(可能非常大)。网页位置的锚定又需要依靠 DOM 结构,因而 DOM 的变化给锚定带来了很大的不确定性。我们需要设计一种机制,来提高锚定的可信度和准确性。
解决思路
人的认知系统天然有模糊匹配的能力,即使是一些微小的改变,我们也能很快地找到他。我们可以借鉴这种模式,设计一种模糊锚定的机制。为了实现这种机制,我们定义三种数据,以提供后续锚定的依据:
- RangeSelector - 准确的节点查询路径
- TextPositionSelector - 文本在文档中的收尾偏移量
- TextQuoteSelector - 文本内容、文本前缀内容、文本后缀内容
RangeSelector
RangeSelector 是一种准确的节点查询路径,它可以准确无误地锚定到文档中的某个节点,因为它包含了开头节点和结尾节点的 XPATH 以及开头节点和结尾节点的偏移量。
XPATH 即 XML 路径语言,它用来提供一种在 XML 文档中定位节点的方式,同样适用于 HTML。
它的结构如下:
interface RangeSelector {
endContainer: string
endOffset: number
startContainer: string
startOffset: number
type: 'RangeSelector'
}
interface RangeSelector {
endContainer: string
endOffset: number
startContainer: string
startOffset: number
type: 'RangeSelector'
}
假设我们有如下的文档结构:
<html lang="en">
<head>
</head>
<body>
<div>hello, <span>world</span>.</div>
</body>
</html>
<html lang="en">
<head>
</head>
<body>
<div>hello, <span>world</span>.</div>
</body>
</html>
当我们锚点在于 “llo, world” 时,我们可以得到如下的 RangeSelector:
{
startContainer: '/html/body/div/text()[1]',
startOffset: 2,
endContainer: '/html/body/div/span/text()[1]',
endOffset: 5,
type: 'RangeSelector'
}
{
startContainer: '/html/body/div/text()[1]',
startOffset: 2,
endContainer: '/html/body/div/span/text()[1]',
endOffset: 5,
type: 'RangeSelector'
}
startContainer 和 startOffset 准确标记了锚点的起始位置,endContainer 和 endOffset 则标记了锚点的结束位置。通过这四个数据可以准确地锚定对应范围。当文档结构没有发生任何改变时,这种锚定方式将始终准确,但它是极其脆弱的,一旦节点发生了变化,这种锚定方式就会失效,如果节点未发生变化,但文本内容改变了,即便通过 XPATH 查询到节点,匹配结果也不是我们要的。
TextPositionSelector
TextPositionSelector 定义了两个值,分别是 start 和 end,它们分别表示文本在文档中的起始偏移量和结束偏移量。它的结构如下:
interface TextPositionSelector {
end: number
start: number
type: 'TextPositionSelector'
}
interface TextPositionSelector {
end: number
start: number
type: 'TextPositionSelector'
}
在此之前,我们需要生成一个 DOM 到文本的双向映射表,该表让我们可以通过文本偏移量快速地找到它所属的 DOM 节点。正如下图所示,它表示了上面的 HTML 文档的 DOM 到 文本 的映射关系:
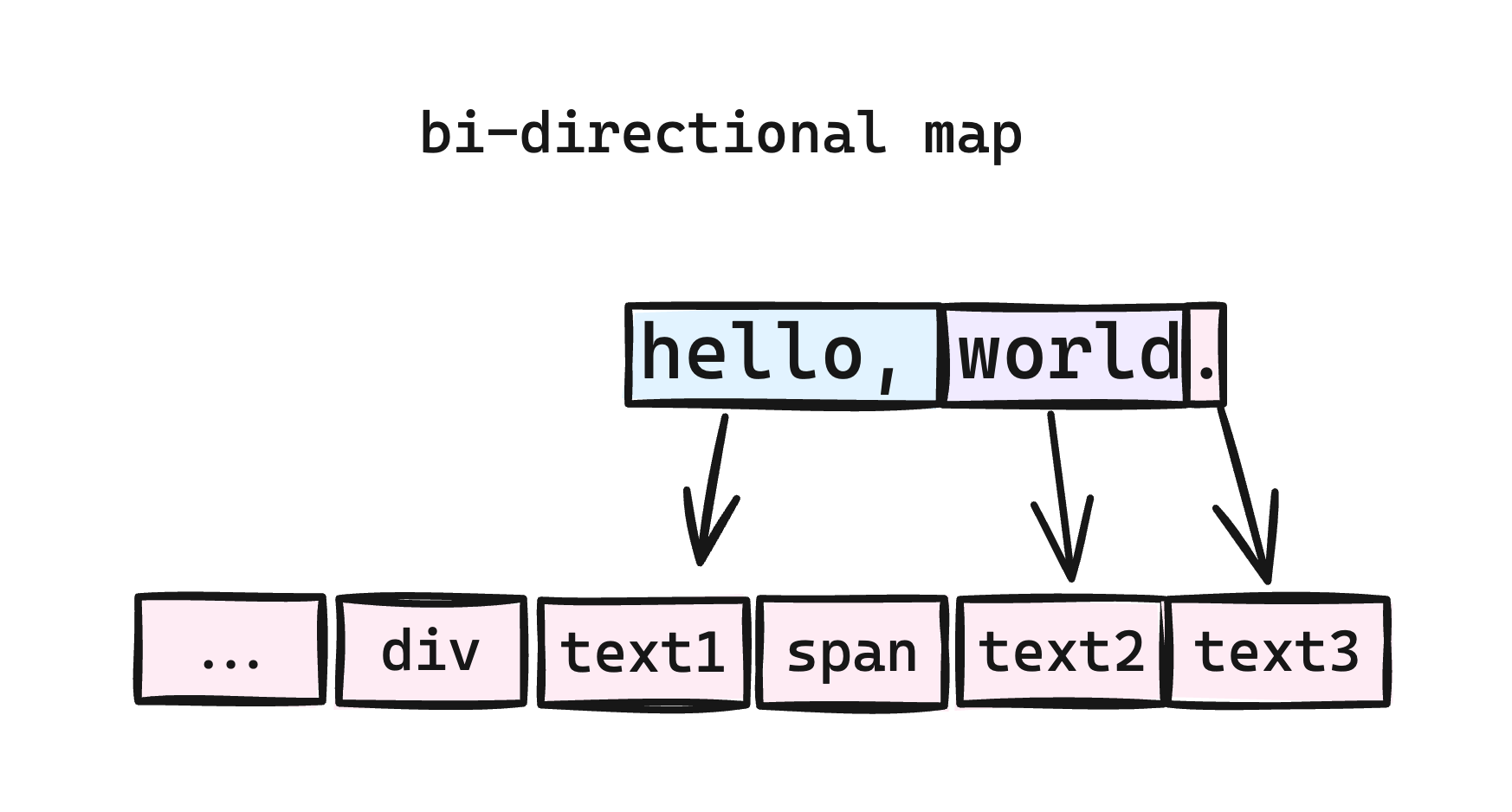
通过某个文本子串就可以确定锚定位置的首尾两个节点。例如,对于 “llo, world” 这个内容,它对应 TextPositionSelector 中的 start 和 end 分别为 2 和 11,通过这两个值可以直接在映射表拿到锚定位置的首尾节点。这种方式使锚点数据不依赖于文档的结构,而始终与文档的文本内容保持一致,当在文档插入媒体节点或修改文本所在节点的样式和类型时,锚点数据仍然有效。但当文本内容改变导致目标文本偏移量发生变化时,锚点数据就会失效。
TextQuoteSelector
RangeSelector 和 TextPositionSelector 两种锚定方式依赖于文档整体的结构和内容,假设锚定范围仅仅只是文档中部或末尾上的局部文本,但文档较前的部份发生了变化,此时它们有很大的概率失效,显然这不太合理。TextQuoteSelector 是一种只与文档局部内容相关的锚定方式,它定义了三个值,分别是 exact、prefix 和 suffix,它们分别表示文本内容、文本前缀内容、文本后缀内容。它的结构如下:
interface TextQuoteSelector {
exact: string
prefix: string
suffix: string
type: 'TextQuoteSelector'
}
interface TextQuoteSelector {
exact: string
prefix: string
suffix: string
type: 'TextQuoteSelector'
}
如果对于以下的文档文本内容:
I have a dream that one day this nation will rise up and live out the true meaning of its creed: "We hold these truths to be self-evident, that all men are created equal."
I have a dream that one day on the red hills of Georgia, the sons of former slaves and the sons of former slave owners will be able to sit down together at the table of brotherhood.
把 “We hold these truths to be self-evident” 作为我们的锚定目标时,TextQuoteSelector是这样的:
{
exact: 'We hold these truths to be self-evident',
prefix: 'its creed: "',
suffix: ', that all m',
type: 'TextQuoteSelector'
}
// prefix and suffix are truncated to 12 characters, but they can be longer
{
exact: 'We hold these truths to be self-evident',
prefix: 'its creed: "',
suffix: ', that all m',
type: 'TextQuoteSelector'
}
// prefix and suffix are truncated to 12 characters, but they can be longer
此时利用 DOM 到 文本 的双向映射表,用 exact、prefix 和 suffix 进行文本搜索得到锚定的首尾节点,以此锚定到目标位置。在这种锚定方式下,即便文档发生了变化,只要 prefix + exact + suffix 仍然存在于文档中,锚点数据就仍然有效。
完整锚定流程
RangeSelector 和 TextPositionSelector 准确性很高,却很脆弱,而 TextQuoteSelector 虽然不需要高度依赖整个文档的结构和内容,但局部上仍然是脆弱的,将三种方式结合起来,并借助额外的模糊搜索算法,可以提高锚定的可靠性。
- 首先使用 RangeSelector 进行匹配
- 如果未查询到结果,则跳过
- 如果查询到结果,则将匹配结果的文本和 TextQuoteSelector 的 exact 进行对比
- 如果两者不同,则跳过
- 如果两者相同,则锚定成功
- 使用 TextPositionSelector 进行匹配
- 如果未查询到结果,则跳过
- 如果查询到结果,则将匹配结果的文本和 TextQuoteSelector 的 exact 进行模糊对比
- 如果两者不相似,则跳过
- 如果两者相似度大于阈值,则锚定成功
- 使用 TextQuoteSelector 的 prefix 和 suffix 进行模糊搜索
- 如果未查询到结果,则跳过
- 如果查询到结果,将中间部分作为匹配结果,并 TextQuoteSelector 的 exact 进行模糊对比
- 如果两者不相似,则跳过
- 如果两者相似度大于阈值,则锚定成功
- 使用 TextQuoteSelector 的 exact 进行模糊搜索
- 如果未查询到结果,则跳过
- 如果查询到结果,则锚定成功
结语
网页锚定的脆弱性来自于网页的 DOM 结构不可控的发生改动,没有一种方式使得 锚点 和 DOM 保持同步,即便有,也需要为 DOM 复杂的逻辑结构提供一种 diff 算法,来对旧锚点进行更新。但即便如此,也无法保证锚点完全准确和可靠。以上的解决思路,是一种折中的方案,它通过多种方式来提高锚点的可靠性,来源于文档标注软件 hypothesis 的具体实现,官网有专门一篇文章来介绍:《Fuzzy Anchoring》,可以参考以获得更多细节说明。